- Tech
Backlog MCP Server を活用してタスク消化してみよう!

本記事ではVSCode Copilot Agent で Backlog MCP Server を利用し、Backlog上に設定された課題の消化方法や、それを踏まえた理想的なBacklogの運用方法について書いていきます。
目次
目次
- MCP Server とは?
- Backlog MCP の設定方法・使い方
- Backlog MCP を使ったタスク消化
- AI開発を見据えたBacklogタスクの書き方
- 「AI開発を見据えたBacklogタスクの書き方」の検証
- まとめ
MCP Server とは?
MCP(Model Context Protocol)は、AI アシスタントが外部のツールやサービスと連携するための標準的な仕組みです。簡単に言うと、AI が様々なアプリケーションと「会話」できるようにする橋渡し役のような存在です。
MCP Server の基本概念
従来の問題
これまで、AI アシスタント(Claude、ChatGPT など)は、基本的に「テキストでの会話」しかできませんでした。例えば:
- 「Backlog の課題を確認して」と言っても、AI は Backlog にアクセスできない
- 「GitHub のコードを見て修正して」と頼んでも、AI は GitHub を直接操作できない
- 「データベースの内容を調べて」と依頼しても、AI はデータベースに接続できない
MCP Server が解決すること
MCP Server は、AI アシスタントと外部サービスの間に立って、以下のようなことを可能にします:
あなた → AI アシスタント → MCP Server → 外部サービス(Backlog、GitHub など)具体的には:
- リソースの取得: 外部サービスのデータを AI が読み取れる形で提供
- ツールの実行: AI が外部サービスの機能を実際に使えるようにする
- プロンプトの拡張: 外部の情報を使って、より賢い回答ができるようにする
実際の動作例
Backlog MCP Server の場合
- あなた: 「今日締切の課題を教えて」
- AI: MCP Server を通じて Backlog API にアクセス
- MCP Server: Backlog から課題データを取得して AI に渡す
- AI: 取得したデータを分析して、わかりやすく回答
Backlog MCP の設定方法・使い方
必要条件
- VSCode(agent mode) / Claude Desktop / Cline / Cursor などのエディター
- Docker
- APIアクセスが可能なBacklogアカウント
- BacklogアカウントのAPIキー(APIキーの取得方法は こちら )
準備ができたら、基本的には Backlog公式のREADME に沿って設定しますが、READMEは Claude Desktop / Cline / Cursor 用に書かれているので、VSCode の agent mode で導入する際には、ワークスペースの.vscode/mcp.json か ユーザー設定の settings.json に以下のように記載します。(Option 1: Install via Docker の場合)

your-domain.backlog.com を実際のBacklogドメインに、your-api-key を実際のBacklog APIキーに置き換えてください。
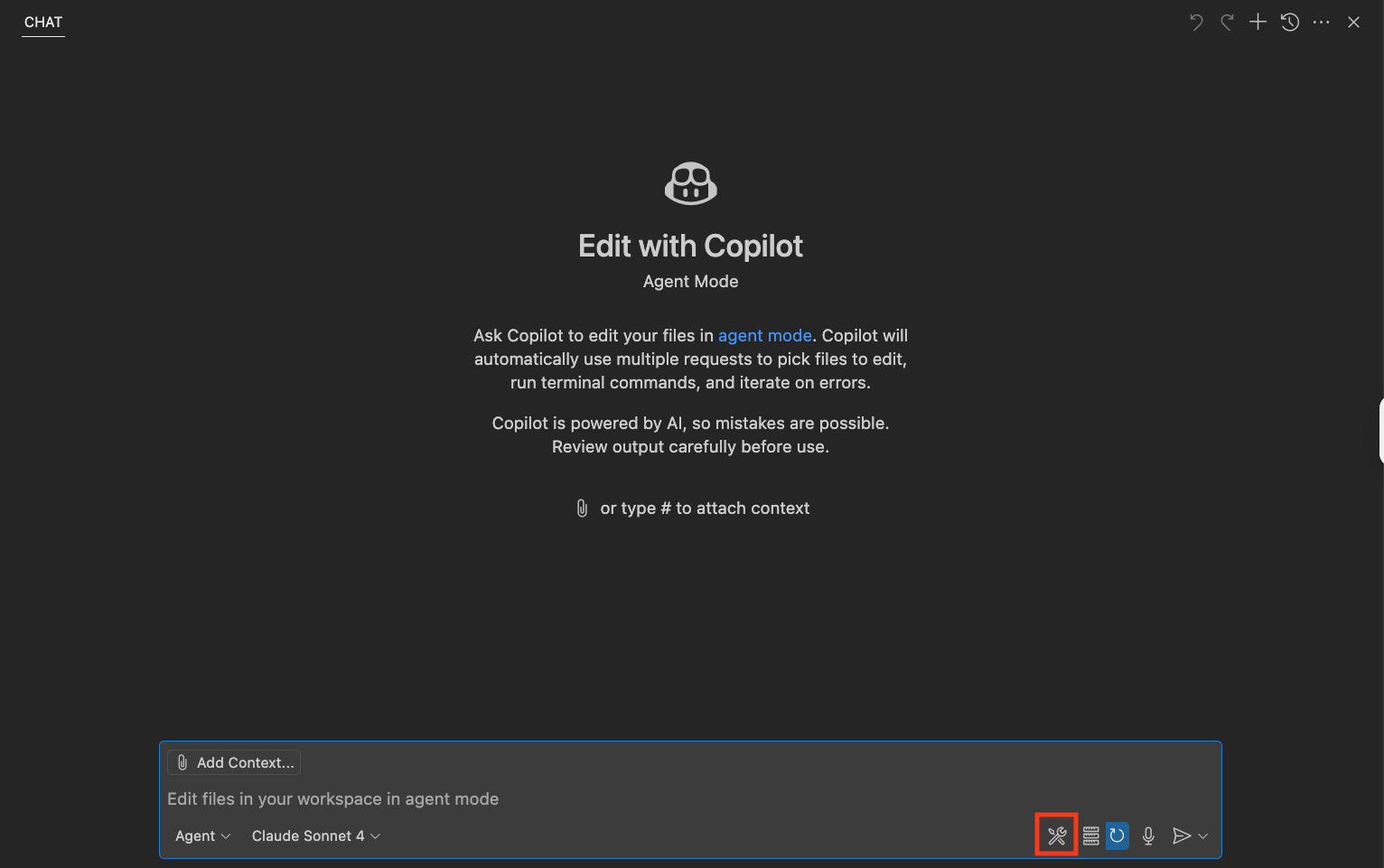
設定が出来たらVSCode を再起動し、copilot chat を開き、 agent mode にします。
工具のマークを押し、Backlog MCP Server が一覧に表示されていたら起動出来ています。

Backlog MCP を使ったタスク消化
それでは早速Backlog MCP を使ってBacklogタスクの消化をしてみましょう。
今回は仮で以下のような課題を作成しました。

余談ですが、ドコドアでは一部案件で Svelte という Javascript/Typescript のフレームワークを使っています。
shadcn-svelte は、 shadcn というUIコンポーネント集のSvelteポートです。
Svelteおよびshadcn-svelte の導入は、shadcn-svelteの公式ドキュメント のコマンドを実行すると簡単にできます。
それでは早速 Backlog MCP Server を使ってみましょう。
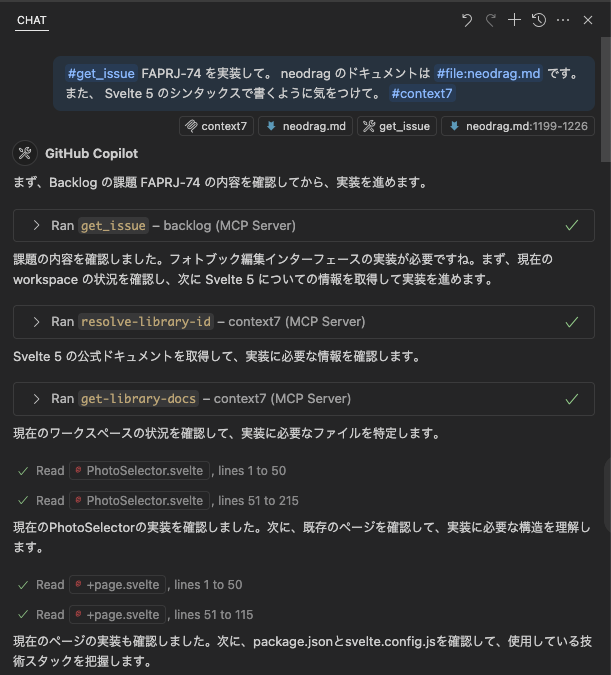
get_issue メソッドを使って課題の内容を取得します。
get_issue [課題キー] というプロンプトを送信します。(モデルは Claude Sonnet 4 です)


ちゃんと課題の内容を取得出来ていますね。
しかも既存コードに shadcn-svelte の drawer や sheet コンポーネントが存在していることも把握してくれています(さすが Claude Sonnet 4)。
それではこのまま get_issue [課題キー] このタスクを実装して #context7という少し雑なプロンプトを送ってみます。
※context7 とは、ライブラリやフレームワークの最新ドキュメントを参照可能にしてくれるMCP Server です。

Backlog MCP によってタスクの内容を把握しつつ、 Context7 によって shadcn-svelte のドキュメントを参照しながら実装してくれています。
今回は運が良かったかもしれませんが、1回のプロンプトで完成しました。

http://localhost:5173 にアクセスして確認します。
PC版:

画像ピッカーがちゃんと画面下部に固定&横スクロールになっていますね。
デザイン的にも shadcn のデザインを踏襲したものになっています。
SP版:

- スマホでは Bottom Sheet として表示する
- 画像を縦スクロールで一覧表示
- 各画像をタップして選択可能にする
をしっかりと守ってくれていますね。スマートフォンでも使いやすそうなUIです。
AI開発を前提に据えたBacklogの運用方法
Backlog MCP Serverを使うと、AIにBacklogタスクの内容をコンテクストとして渡せる事がわかりました。
では実際にAIにBacklogタスクを実装させるとして、どのように記述するのが望ましいのでしょうか。
私としては、以下のポイントを抑えた書き方を提案したいと思います。
✅ 1. ゴール(目的)を明記する
何を実現したいか、完了条件を1-2行で明記
例
ユーザーがプロフィール画像をアップロードできるようにする。画像はS3に保存し、アップロード後にプレビューを表示する。
📝 2. 具体的な仕様・要件を書く
- 必須要件(必ず実装するべき内容)
- オプション要件(できれば対応してほしい内容)
- 入力・出力・エラー時の振る舞い
例
- 画像フォーマット: png, jpg, jpeg
- 最大ファイルサイズ: 5MB
- 成功時: プレビューURLを返す
- 失敗時: エラーメッセージを返す(例: “ファイルサイズが大きすぎます”)
⚙️ 3. 技術的条件・制約を書く
- 使用するフレームワークやライブラリ
- 既存のコードとの関わり
- コーディングスタイル(例: ESLint 準拠、TypeScript strictモードなど)
例
- Next.js + TypeScript を使用
- s3-upload.ts という共通モジュールが既に存在
- eslint のルールに従うこと
🧪 4. テスト観点を書く
- どのようなテストケースをカバーしてほしいか
- ユニットテスト、統合テスト、E2Eテストなど
例
- 画像が正常にアップロードされ、S3に保存されること
- ファイルサイズ超過時にエラーになること
- サポート外形式でアップロードできないこと
💬 5. 補足・参考情報
- 参考リンク(ドキュメント、Figma、API仕様など)
- 既存の類似Issue
- 関連PR
例
- Figma: https://figma.com/xxxx
- API仕様書: https://example.com/api-docs
デザイン系のタスクでFigmaで明確なデザインが決まっているなら、そのURLを提示するといいですね。
FigmaにもMCP Server が用意されているので合わせて使う事でデザインをFigmaに合わせてAIに開発させられます。
まとめると、
- 目的(概要)– 何を実現したいか
- 必須要件とオプション要件 – 実装の優先度を明確化
- 使用する技術・制約 – 技術スタックと制限事項
を必須で書いて、テスト観点はそのプロジェクトで必須であれば、デザイン情報は用意があれば書く、といった形になります。
「AI開発を見据えたBacklogタスクの書き方」の検証
それでは前述の運用方法で上手くいくか検証するためにもう1つ以下のBacklog課題を先述のフォーマットに沿う形で作成しました。
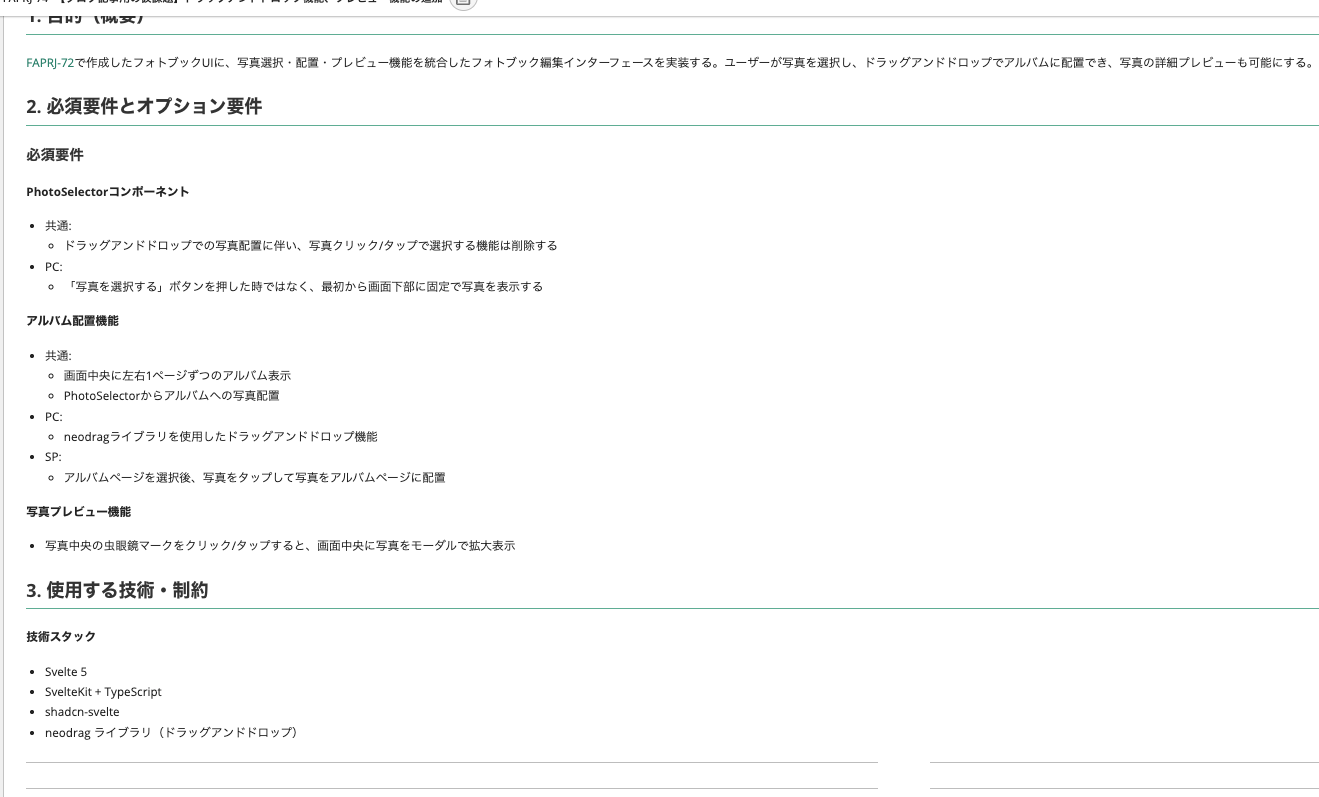
PCではドラッグアンドドロップによる写真配置、
SP版ではドラッグアンドドロップは難しいだろうと判断し、タップで写真を配置する要件です。
この課題をAIにやってもらいます。
neodrag というドラッグアンドドロップ用のライブラリに関しては、公式ドキュメントをダウンロードしてMarkdownファイル化したものを渡しています。
一発で以下のような感じになりました。
PC:
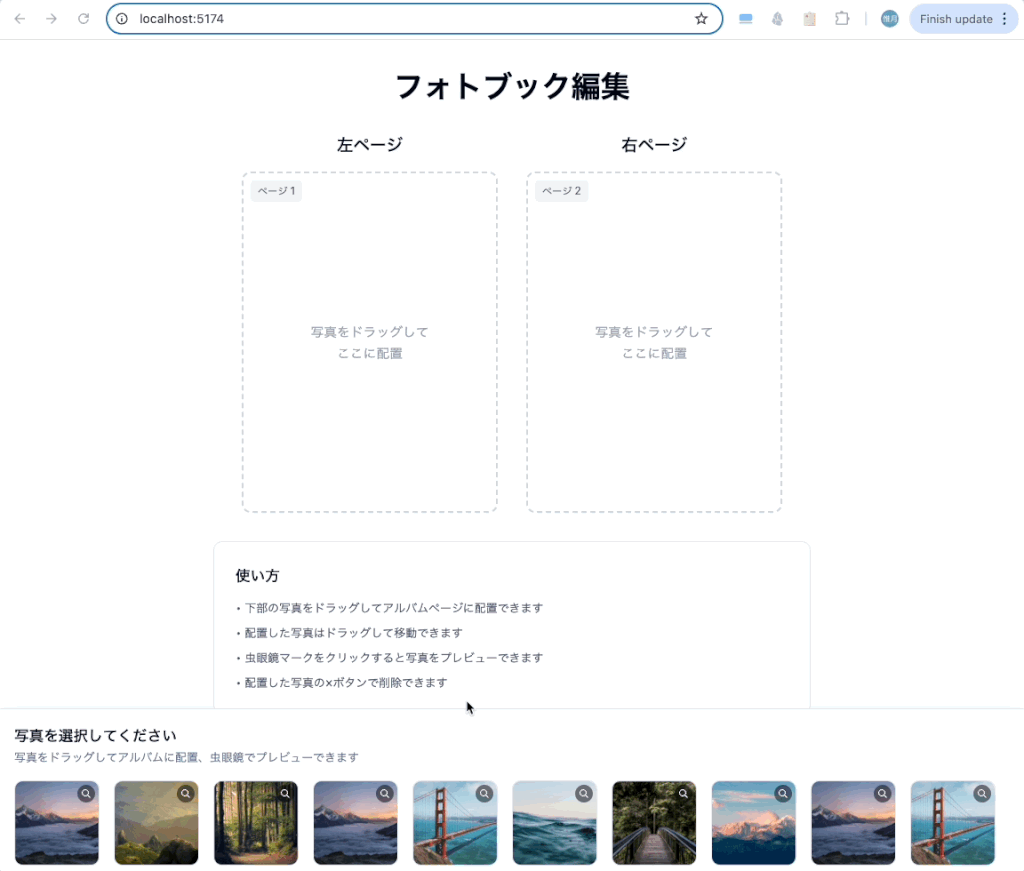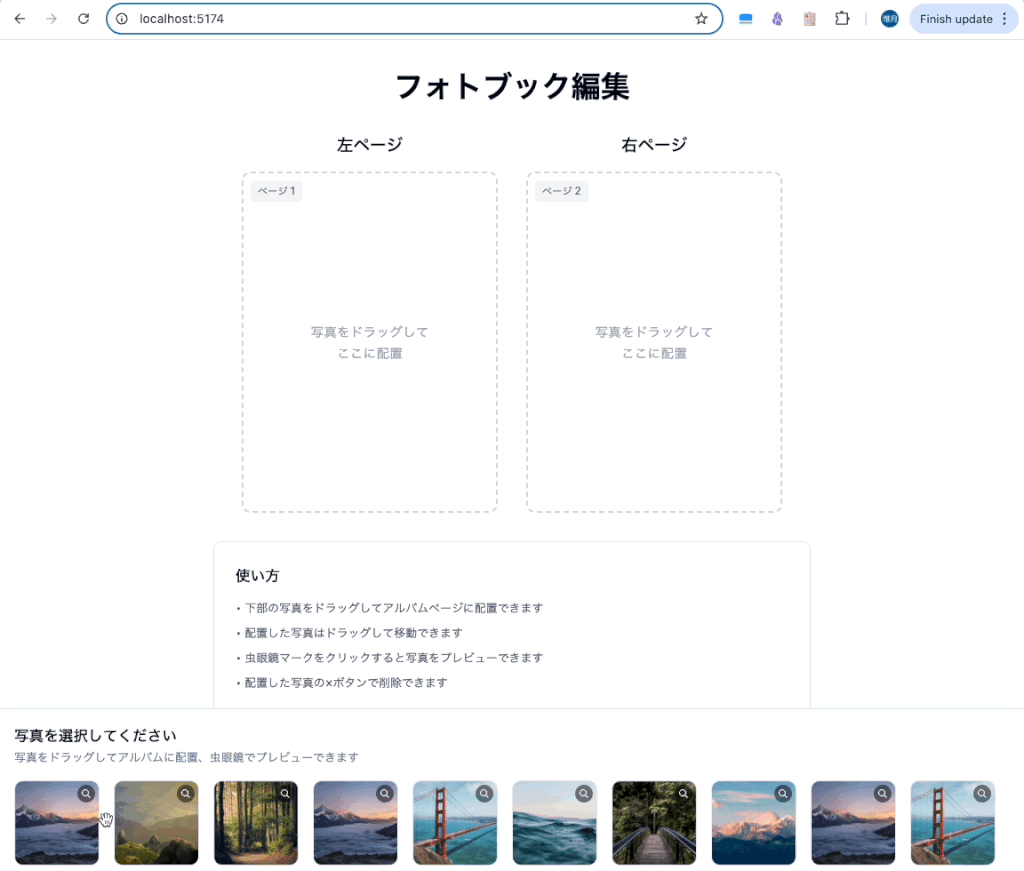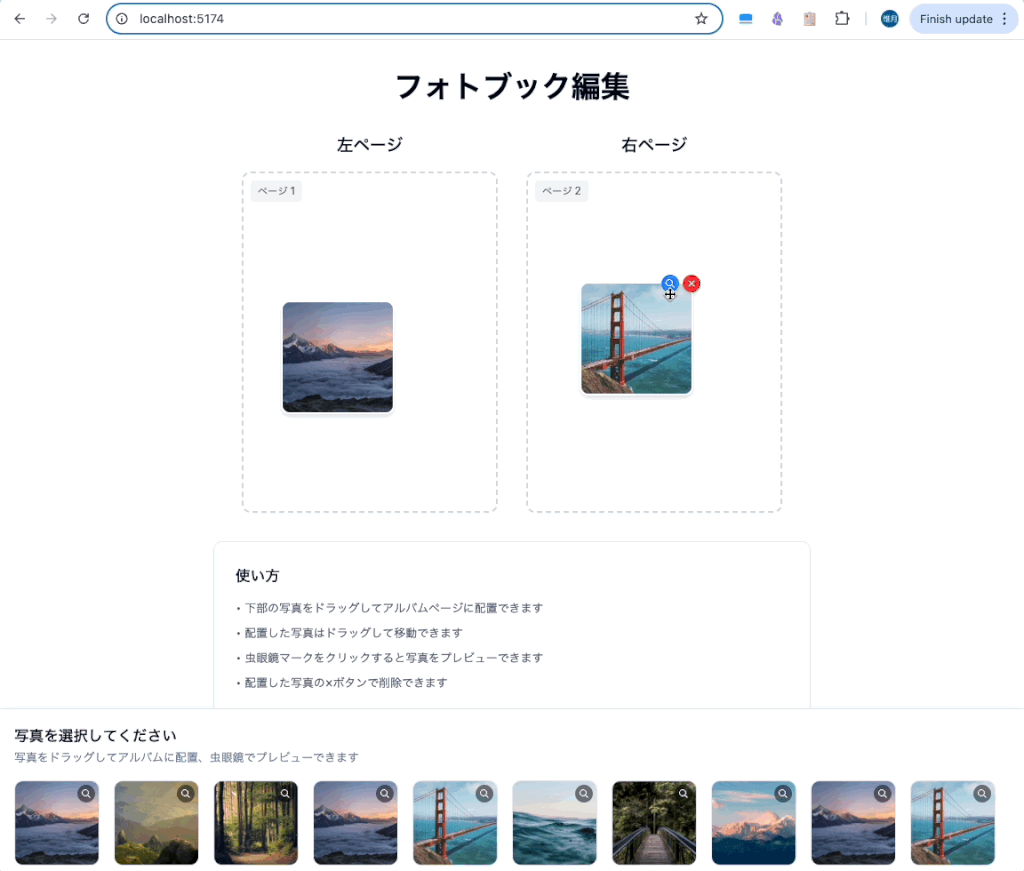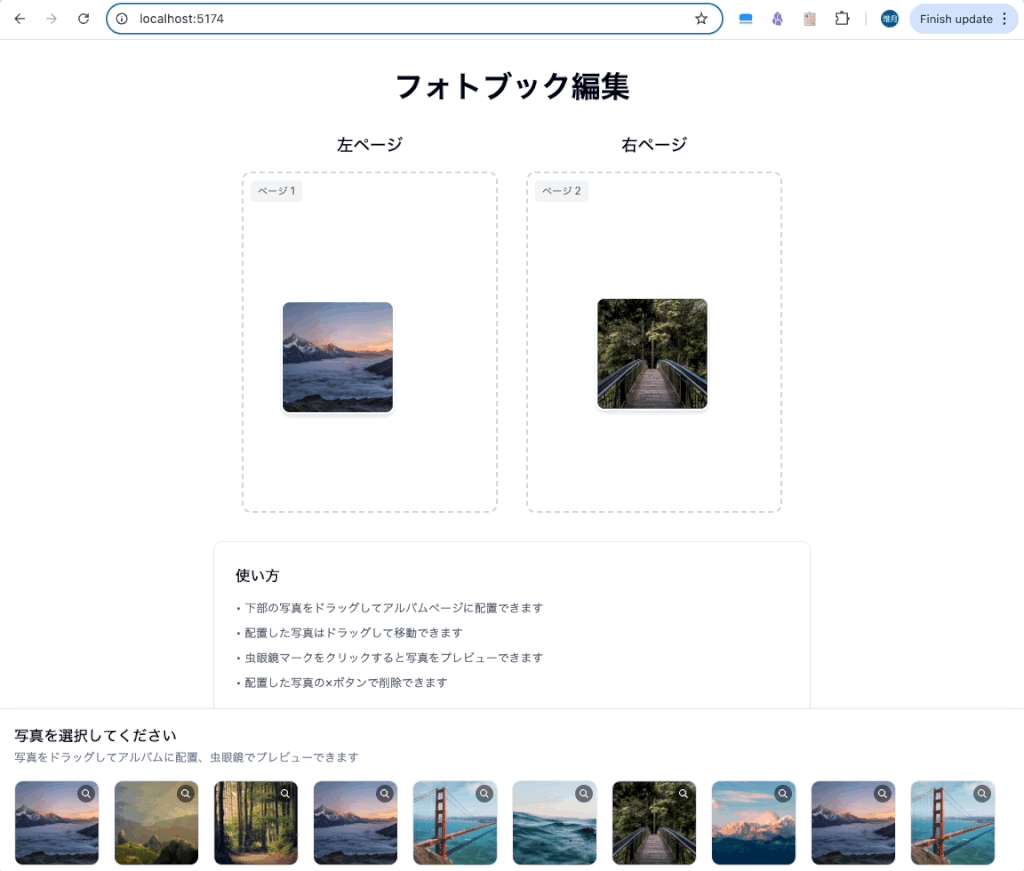
アルバムに配置した後にページ一杯のサイズになってほしいところですが、
- 写真の拡大
- ドラッグアンドドロップでの写真配置
- 配置した写真の削除
が出来ていますね。
SP:

こちらも配置した後の写真のサイズは気になりますが、
ちゃんとSP版ではドラッグアンドドロップではなくタップでの配置になっていますね。
ちょっとこのままだと収まりが悪いので、「アルバムに写真を配置した時に、写真がそのアルバムのページ一杯のサイズになってほしい。
それをするためには、アルバムのページのサイズも調整が必要。」というプロンプトで修正してもらいました。


PC・SP共に写真がページ一杯になっていい感じなりました。
ということで、「AI開発を見据えたBacklogタスクの書き方」は多少複雑なタスクでも対応出来ることがわかりました。
余談ですが、アルバムページをもっと増やし、1ページに2枚の写真を配置可能なページも作れるのか試しました。
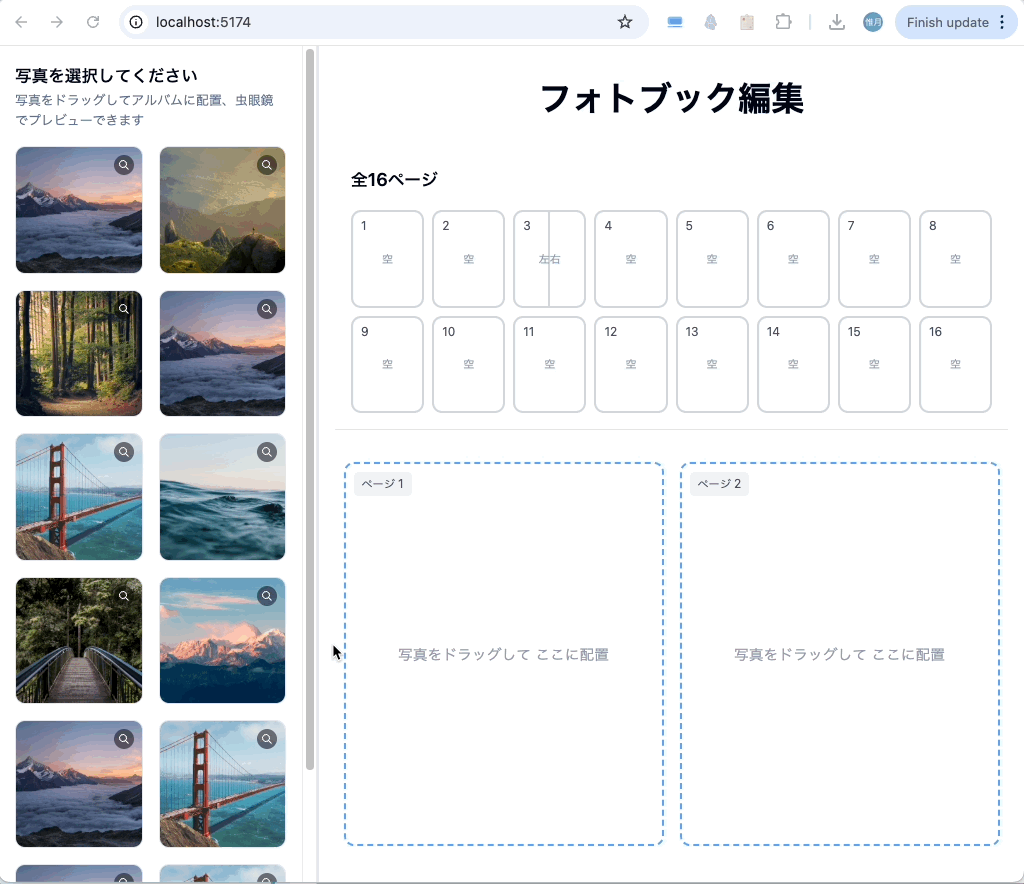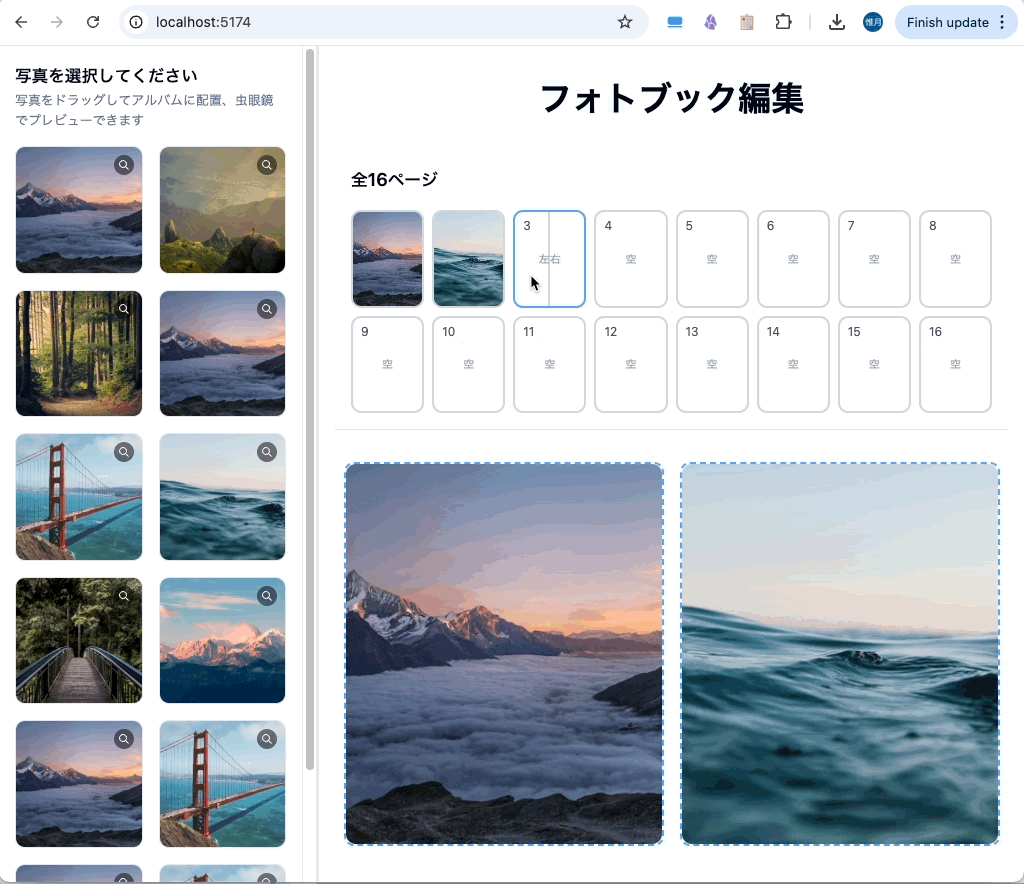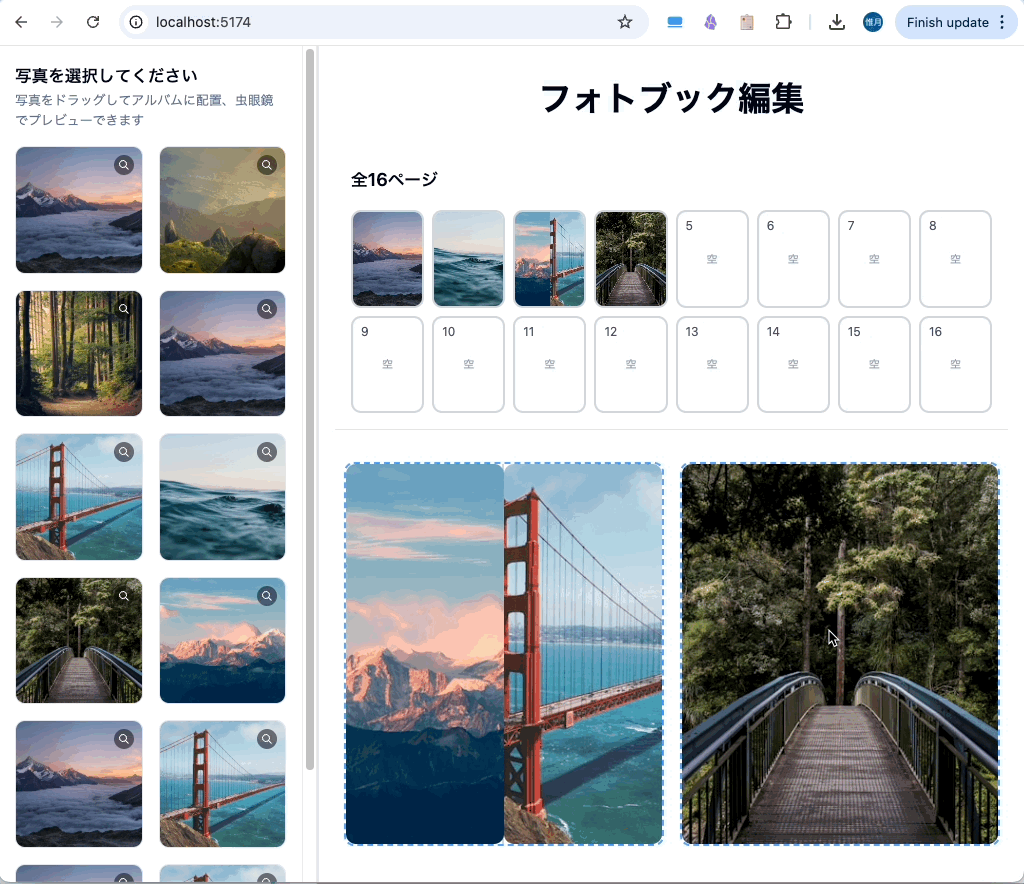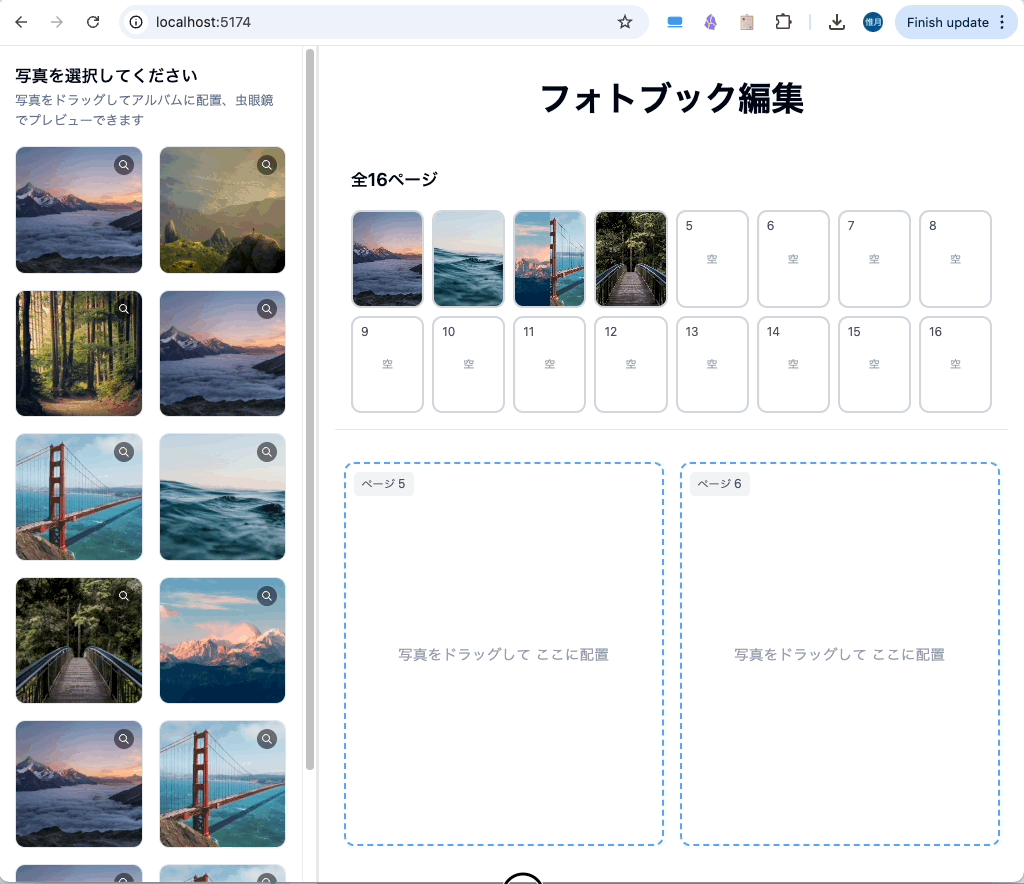
こういう複雑なUIでも作れる Claude Sonnet 4 すごいですね。
まとめ
今回は、Backlog MCP Server を活用してAIにタスクを消化させる方法について解説しました。
普段からBacklog課題を詳細設計書として運用していた場合、追加で利用するライブラリの情報を記載するだけで済むため、比較的スムーズに導入できるでしょう。
ただし、この手法を効果的に活用するには、課題作成者が詳細設計書を書けるスキルと、実装の詳細をある程度理解している必要があります。とはいえ、Backlog課題を詳細に記述することは、AI活用の有無に関わらず実装者にとってメリットがあるため、積極的に取り組んでいきたい施策です。
Backlog MCP以外にも、Context7、Figma MCP、Playwright MCPなど、様々な役に立つMCP Serverが提供されています。これらもあわせて活用を検討してみてはいかがでしょうか。

ドコドア エンジニア部
このブログでは、アプリ開発の現場で培ったフロントエンド、バックエンド、インフラ構築の知識から生成AI活用のノウハウまで、実践的な情報をアプリ開発に悩む皆様へ向けて発信しています!
【主な技術スタック】 Flutter / Firebase / Svelte / AWS / GCP / OpenAI API








