- マーケティング
- 生成AI
- SEO
LLM構造化データとは?生成AI時代のSEOに必要な実装方法と活用ポイント

Web運用担当者・マーケティング部門の皆さまにとって、検索エンジン経由での流入改善、クリック率(CTR)向上、ブランド信頼獲得などは日常的な課題です。
ここ数年で「AI検索」「生成AIによる回答」「チャットボット型検索インターフェース」などが急速に普及する中、単に「Googleの上位表示」だけではなく、「AIモデルに使われる・抜き出されるコンテンツ」になることの重要性が増しています。
本記事では、そんな変化を踏まえて「LLM(大規模言語モデル)/LLMO(Large Language Model Optimization)」「構造化データ(Schema マークアップ)」「SEO/AI時代での両立」について整理し、具体的な実装方法・運用ポイントを提供します。
貴社の Webサイト運用/マーケ施策にとって、次のような問いに「はい」と答えられるようになるために、ぜひ最後までお読みください。
-
「当社のコンテンツは、AIチャットボット型ツールに引用・参照され得る設計になっているか?」
-
「構造化データを適切に実装し、AIにも検索エンジンにも読み取られやすいか?」
-
「生成AI時代において『抜き出される/引用される』ための体制があるか?」
このような問いに対して「準備できている」と言える状況は、従来のSEO施策だけでなく、“AIがコンテンツをどう読み取るか”を意識した運用へと転換していくことを意味します。
本記事が、その転換の羅針盤となれば幸いです。
目次
LLMO時代におけるSEOと構造化データの関係
LLM(大規模言語モデル)/LLMO(Large Language Model Optimization)とは何か
「LLM(Large Language Model)」とは、膨大なテキストデータを学習して、自然言語の生成・理解を行うモデルを指します。例えば ChatGPT や Gemini のような生成AIも、LLMの応用例です。
「LLMO(Large Language Model Optimization)」は、直訳すれば「大規模言語モデル最適化」。Webコンテンツを、AIモデル(LLM)が読み取り・要約・再利用しやすい形に最適化する手法/考え方を指します。
GoogleのAI overview、AI モードやAIのモデルは、単なるキーワードの羅列ではなく、「文脈・意味・構造」を理解して情報を抽出します。
AI Overviewに関する情報は「AI Overview時代のSEO戦略はどう変わるのか?」で詳しく解説しています。
また、AI モードに関しては「AIモード日本語展開:AI Overviewsの違いと検索の未来予測」で紹介しています。
たとえば、AIに「新潟でSEOに強い制作会社を教えて」と尋ねたとき、AIが参照するのは単なる文章ではなく、「企業の所在地」「サービス内容」「実績」「信頼性」といった構造的情報です。

そのため、AIが読み取りやすい形でデータを整理することが、SEOにもAI引用にも効果的なのです。
なぜ構造化データが重要なのか-AI検索・生成AI時代に構造化データの意義が増している理由
構造化データ(Structured Data)とは、Webページ上の情報を機械が理解しやすい形式でマークアップする手法を指します。
Googleや生成AIは、Webページをクロールして内容を解析しますが、人間のようにニュアンスを完璧に理解できるわけではありません。
その際に、Webページ上の構造(見出し/段落/箇条書き/マークアップ)を読み取りやすいほうが、抜き出されて参照される可能性が高くなります。LLMO の観点からも「構造・意味・出典の明示」が重要とされており、構造化データはその一環です。
また、生成AI回答が「要約/抜粋」されて提供される場合、原典となるWebページが整理されており、抽出されやすい構造を持っていれば、AI回答として参照される確率が上がります。構造化データは、その「抜き出される設計」として機能します。
さらに、ユーザーの検索行動自体も変化しています。
チャット型検索・音声検索・生成AIインターフェースが増えており、「リンク先をクリックして読む」だけではなく「AIに質問してその場で回答を得る」スタイルが広がっています。
そうした環境下では、リンク先ページがAIにとって読み取りやすく、マークアップがされていることが、競争優位になり得ます。
以上のように、構造化データは単なる「検索エンジン向けのマークアップ」ではなく、「AI時代の抜き出されやすさ/引用されやすさ」を担保するための技術的基盤と位置づけられます。
構造化データの重要性 —— Web担当者・マーケ担当者が要点を押さえておくべきポイント
構造化データとは何か(定義・形式・導入フォーマット)
構造化データとは、Webページの中に記載された情報を、機械(検索エンジン、AIモデル)が理解しやすい形でマークアップするためのデータ構造を指します。具体的には、以下の要素があります。
-
定義:Webページの中で、「この部分はこのタイプの情報(例:FAQ、手順、製品情報)です」と明示するためのマークアップ。
-
形式:代表的なものに JSON-LD(JavaScriptで埋め込む形式)、RDFa、Microdata があります。JSON-LD が現在もっとも推奨される形式です。
-
導入フォーマット:例えば、以下のようなコードをページ内
<head>または<body>に記載します。

このように記述することで、Googleも生成AIも「質問と回答のセット」であることを理解しやすくなります。
構造化データがもたらすSEO・LLMO上のメリット(可視性・クリック率・AI引用)
Web担当者/マーケ担当者が押さえておくべき構造化データ導入のメリットを整理します。
可視性の向上
リッチリザルト(例:FAQリスト、How-To手順表示、リッチスニペット)として検索結果上で目立つ形で表示されることがあります。これにより、自然検索のクリック率(CTR)改善が期待できます。
参考:Google Search Central「Google 検索における構造化データマークアップの概要」
AIによる引用・抜き出しの可能性向上
生成AI/チャットボット型インターフェースでは、内容を“どのデータから抜くか”“どの情報が明確にタグ付けされているか”を参照する傾向があります。構造化データを入れておけば、AIにとって「このページのこの情報は○○タイプ」と分かりやすくなるため、抜き出され・参照される可能性が高まります。例えば、LLMO観点で “Entity + Schema” の構造を整えることが推奨されています。
ユーザー体験(UX)の向上
構造化データの記述により、FAQ形式・手順形式・記事形式などが整理されていれば、ユーザーが Webページ上で必要な情報を見つけやすくなります。これは直帰率の低下・滞在時間の改善に寄与します。
将来のAIプラットフォーム対応力強化
今後も“AIがユーザーの情報アクセス手段として主流に”なると予想されており、その中で「AIがコンテンツを抽出しやすい設計」であることは競争優位となります。
導入時の注意点・落とし穴
構造化データ導入には次のような注意点・落とし穴もあります。どの内容もWeb担当者/マーケ担当者として確認しておくべき内容です。
前提として構造化データは「手段」であり「目的」ではありません。
目的は「AI時代・Web時代においてユーザーとAIどちらにも読みやすいコンテンツ設計を行う」ことにあります。
誤ったマークアップの実装
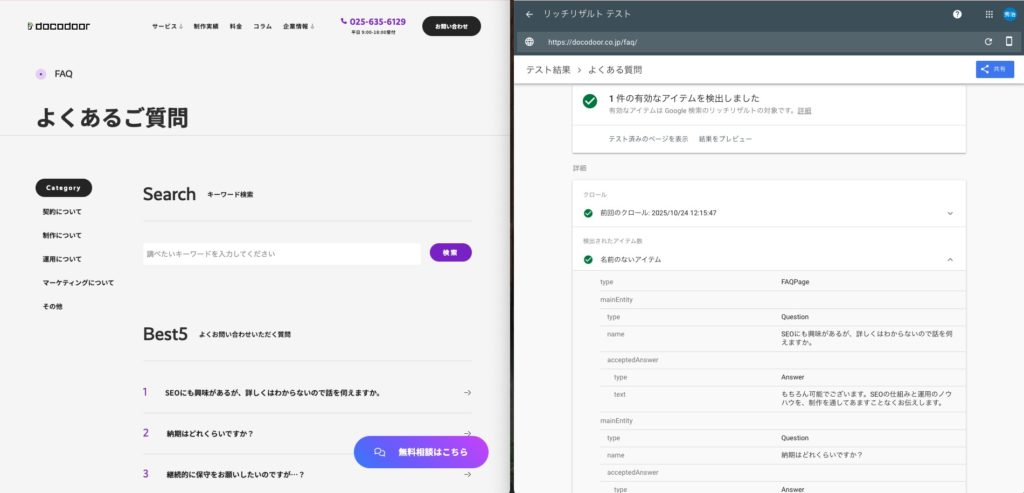
構造化データの形式やタイプを誤ると、逆にエラー表示が出る、あるいはリッチリザルト対象外となる可能性があります。実装後には Google リッチリザルトテスト などで検証を行うべきです。
参考:Google「リッチリザルトテスト」
構造化データだけに頼らない
構造化データを入れたから順位が上がる、という保証はありません。実コンテンツの質・ユーザー体験・リンク・内部構造最適化など従来のSEOも併せて行う必要があります。
過剰マークアップ/不自然なマークアップ
マークアップはあくまで「正確にそのページの内容を機械に伝える」ためのものです。過剰すぎるマークアップや、ユーザー本文と乖離したマークアップはペナルティ対象になる可能性もあります。
継続的なメンテナンスが必要
ページの内容が更新されたら、構造化データも併せて更新が必要です。古くなったマークアップを放置すると、ユーザーおよびAI・検索エンジン双方に誤解を与える恐れがあります。
サイト全体の技術的基盤の整備
構造化データを読み込ませるためには、ページのクロール/レンダリングが適切にできていること、JSON-LDがコンテンツと整合性を保っていること、スピード・モバイル対応・セキュリティ(HTTPS)などが前提となります。
代表的な構造化データの種類と使いどころ
Webサイト運用・マーケティング担当者として、よく用いられる構造化データタイプとその典型的な使いどころを整理します。各場合において、どのようなページに適用すべきかも解説します。
FAQPage(よくある質問ページ)
-
タイプ:
@type: FAQPage。 -
使いどころ:サービス紹介ページのよくある質問欄、製品仕様や価格、契約条件、サポート体制についての Q&A 形式コンテンツ。
例えば、サイトの「よくある質問」一覧ページに FAQPage マークアップを入れることで、検索結果で FAQ スニペット表示される可能性が高まり、読者の離脱を防ぎやすくなります。 -
利点:質問→回答という構造がAIや検索エンジンにとって「どこが質問で、どこが回答か」が明確なので、引用・抜き出しされやすい形式です。LLMO観点でも FAQ 形式のマークアップは推奨されています。
HowTo(手順解説ページ)
-
タイプ:
@type: HowTo。 -
使いどころ:操作マニュアル、サービスの利用フロー、導入・申請手順、トラブルシューティング手順など。
例えば、お問い合わせからサービスの導入実施、アフターフォローまでのステップを整理したページにこのマークアップを実装。 -
利点:手順形式のページはリッチカード(手順表示)として検索・AIに抜き出される可能性があります。構造的に「何を」「どのように」「どんな結果か」が整理されているため、AIにとっても整理しやすい情報源となります。
Article(記事一般)/BlogPosting(ブログ記事)
-
タイプ:
@type: Articleまたは@type: BlogPosting。 -
使いどころ:コラム記事、ニュースリリース、社内ブログ、メディア掲載ページなど。
例えばこのような「構造化データ」記事自体を「BlogPosting」タイプでマークアップすると、検索エンジン・AIいずれでも「この記事は○○について書かれている」という構造が明確になります。 -
利点:情報の発信源を明示できるため、信頼性・権威性(E-E-A-T)向上の一助となります。さらに、AIが“この記事を参照しました/引用可能です”と判断しやすくなります。
Organization / Person / ProfilePage(企業/人物情報)
-
タイプ:
@type: Organization、@type: Person、@type: ProfilePage。 -
使いどころ:会社概要ページ、代表者メッセージページ、経営陣紹介、採用サイトの人物紹介など。
例えば、「会社概要」ページに Organization マークアップを付与します。 -
利点:ブランド/組織/人物という「実体(Entity)」を明示でき、AIモデルが「このページはこの組織/人物について書かれている」と理解しやすくなります。LLMO観点でも「エンティティ(Entity)最適化」が注目されています。
その他(BreadcrumbList/Product/Event など)
-
@type: BreadcrumbList:パンくずリスト構造を検索エンジンに明示するためのマークアップ。特にECサイト・大規模サイトでの階層構造可視化に有効。 -
@type: Product:ECサイト、製品紹介ページで使われる、価格・レビュー・在庫などを示すタイプ。 -
@type: Event:イベント案内ページ(展示会、ウェビナー、セミナー)などに適用。
これらも、該当ページがあるならば構造化データの対象となり、AI・検索双方にとって情報整理の助けとなります。
上記に示したような、代表的な構造化データのタイプと使いどころを押さえておけば、Web運用担当・マーケ担当として「このページにはどのタイプが適用できるか」を判断しやすくなります。
構造化データの活用ポイント:実装方法から運用まで
実装手順と技術フォーマット(JSON-LD 推奨)
構造化データを実装する際の手順と技術フォーマットについて、具体的に解説します。
-
対象ページの整理
まず、どのページ/どのコンテンツが構造化データ導入の対象かを洗い出します(例:FAQ、HowTo、記事、会社概要、製品紹介など)。
-
マークアップタイプの選定
上記第4章のように、ページの内容に応じて
FAQPage、HowTo、Articleなど適切なタイプを選びます。 -
コード作成(JSON-LD)
JSON-LD形式は現在、検索エンジン各社でも推奨されており、管理・保守性・HTMLとの分離性から使いやすいフォーマットです。
- ページへの挿入
作成した JSON-LD を対象ページ内(通常<head>または<body>タグ直下)に挿入します。WordPress など CMS を利用している場合、テーマのヘッダー/カスタム HTML/プラグイン(例:Schema プラグイン)で管理可能です。 - 検証
挿入後、Google の リッチリザルトテスト や構造化データテストツールでエラーがないか確認します。検証に合格していれば、検索エンジン・AIに正しく読み込まれる可能性が上がります。
参考:Google「リッチリザルトテスト」 - 運用・メンテナンス
コンテンツ更新時には、構造化データも併せて更新します。また、検索エンジンの仕様変更や新しいタイプの登場にも注意を払います。
Webサイト運用担当がやるべき設定チェックリスト
運用時に使えるチェックリスト形式にまとめます。社内で共有・運用フロー化すると効果的です。
-
対象ページの選定:FAQ/HowTo/記事/会社概要/製品紹介など。
-
ページタイプに応じたマークアップタイプの選定。
-
JSON-LD or Microdata形式の作成。JSON-LD推奨。
-
HTML挿入位置の確認(
<head>または<body>)。 -
検証ツール(Google リッチリザルトテスト 等)でエラー/警告がないか確認。
-
内部リンク構造の確認:関連ページへのリンクが適切か。
-
ページ読み込み速度・モバイル対応・HTTPSなど技術的な基本が整っているか。
-
コンテンツ更新時の構造化データ修正対応フローがあるか。
-
構造化データがページ本文(visible content)と整合しているか/本文と乖離がないか。
-
リッチリザルト出現などの表示状況を定期的にチェック。
-
AIアクセスログ/AIツール参照状況(可能であれば)をモニタリング。
このチェックリストを定期的に運用し、社内ワークフローとして組み込んでおくことが、構造化データ活用を“点”ではなく“継続的な仕組み”に変える鍵です。
生成AIコンテンツと構造化データの組み合わせによる活用ケース
生成AI(例:ChatGPT、Gemini、AIチャットボット)と構造化データをどのように組み合わせて活用できるか、実例を挙げてご紹介します。
-
ケース①:FAQコンテンツ+FAQPageマークアップ
サービス導入前後に多く寄せられる質問を生成AIで洗い出し、FAQ形式でまとめ、FAQPage構造化データを実装。結果、検索結果だけでなく、生成AIの回答候補として抜き出される確率が上がる。 -
ケース②:HowToコンテンツ+HowToマークアップ
例えば「展示会ブース設営の手順」「Webサイトリニューアルのステップ」など、手順を明確に整理し、HowToマークアップ。生成AIが「手順を教えて」と聞いた時に、貴社ページ内容を構造的に参照する可能性が出てくる。 -
ケース③:コラム/ブログ記事+BlogPostingマークアップ+内部リンク構造
本記事のようなコラムを BlogPosting タイプで構造化し、他の記事(例:「Webアクセシビリティ基本ガイド」)などへの内部リンクを張っておく。これにより、生成AIが「関連情報も探す」際に、貴社サイト内リンク構造を辿りやすくなる。 -
ケース④:ブランド/組織情報+Organizationマークアップ
例えば「会社概要」「採用サイト」などで Organization や Person をマークアップし、ブランド・人物というエンティティを明示。生成AIがブランド・組織名で参照する際の“信頼のスコープ”を高める。
このように、生成AIコンテンツ(ユーザーがチャットで質問→AIが回答)と構造化データの組み合わせは、「AIに引用されるための設計」として強力です。
AI生成コンテンツをそのまま公開するのではなく、人の知見で監修した一次情報に構造化データを組み合わせると、AIに引用されやすくなります。
Googleは「E-E-A-T(経験・専門性・権威性・信頼性)」を重視しており、AIが理解しやすい構造+人間の経験情報が最も評価されます。
上記内容については「生成AIを活用したSEO対策:検索順位とAIによる引用を両立させる戦略」で詳しく解説しています。
効果測定と改善のための指標(検索順位・AI引用可否・CTR)
実装・運用した構造化データ/LLMO対応施策の効果を測定し、改善に活かすには、次のような指標を押さえておくべきです。
検索順位(従来SEO)
構造化データを実装したページのキーワード順位の推移。例えば「LLM 構造化データ」での順位変動。
クリック率(CTR)
リッチリザルトが表示された場合、いわゆる “スニペット表示” の CTR を Google Search Console で確認。構造化データ実装前後で比較。
AI引用/抜き出し可否
生成AI(Google AI mode、ChatGPT等)に実際に「この問い」を投げてみて、貴社ページが回答に使われているか、参照されているかを定性的にチェック。さらに、「AIチャットからの流入」「AIツールを経由したトラフィック(可能なら)」を GA4 等で把握する。例えば、AI検索からの流入が開始しているかどうか。
サイト滞在時間・直帰率・スクロール深度
構造化データを入れたページがユーザーにとって読みやすくなっているかを確認。
内部リンク/マークアップエラー率
構造化データの検証ツールでエラーが出ていないか、サイト内リンク構造が適切か。
更新頻度/メンテナンス状況
マークアップの古さ(例:日付更新されていない)やリンク切れがないか。
このように、定量的に追えるもの(検索順位・CTR・滞在時間)と、定性的に確認すべきもの(AIに参照されているか)を併せて管理することで、構造化データ/LLMO対応が実際に機能しているかを判断できます。
まとめ——構造化データはAI検索時代のSEO/LLMO基盤
構造化データは、もはや「SEO上級者向け」ではありません。
生成AIが普及した今こそ、すべてのWeb担当者が理解すべき基礎要素です。
そして、構造化データを最大限に活用するには、「AIに伝える設計」と「人の信頼性ある情報発信」を両立させることが鍵になります。
本記事が、貴社(および読者である Web運用・マーケティング担当者)にとって、「LLM/構造化データを理解し、実装し、活用する」ための実践的なガイドとなれば幸いです。
AI時代のマーケティング戦略にお悩みの方へ
・SEOや広告の効果が薄れてきている気がする
・生成AIに対応したマーケティングの設計をしたい
・AIモードやAI overviewsに参照されたい
そんな企業様に、docodoorはAI時代に対応したマーケティング戦略をご提案します。
AI時代の検索ニーズ多様化に向けて、構造化データを整備し、AIにもユーザーにも選ばれるサイト運用を始めてみませんか?
下記お問い合わせフォームよりお気軽にご相談ください。
▼ホームページ
https://docodoor.co.jp/seo-2/
▼お問い合わせ・ご相談はこちら
https://docodoor.co.jp/lp_marketing/#contact
よくあるご質問(FAQ)
Q1. LLM構造化データとは何ですか?
A. LLM構造化データとは、生成AI(ChatGPTやGeminiなど)がWebページの内容を正確に理解・引用できるように、情報を整理して記述するデータ形式のことです。
Googleが推奨する「構造化データ(schema.org)」を活用することで、AIが「これはFAQ」「これは企業情報」と認識でき、SEOとLLMO(Large Language Model Optimization)の両方に効果があります。
Q2. 構造化データを導入すると、どんなメリットがありますか?
A. 主に以下の3つのメリットがあります:
-
検索結果にリッチリザルト(★付きレビューやFAQなど)が表示され、CTR(クリック率)が上がる。
-
生成AIに正しく理解され、AI回答や引用に選ばれやすくなる。
-
サイト全体のE-E-A-T(経験・専門性・権威性・信頼性)が強化される。
特に、SEOとAI検索の両方で「選ばれるコンテンツ」を目指す場合は必須です。
Q3. 構造化データはどのページに設置すればいいですか?
A. すべてのページに設置する必要はありません。
目的に応じて次のように選ぶと効果的です:
-
会社概要ページ → Organization
-
サービス紹介ページ → Service
-
ブログ記事・コラム → Article/BlogPosting
-
よくある質問ページ → FAQPage
-
手順記事やノウハウ記事 → HowTo
(参考:本ブログ「代表的な構造化データの種類と使いどころ」)
Q4. LLM構造化データは自分で設定できますか?
A. HTMLの知識があれば手動で設定できますが、正確性が求められるため、SEO会社や制作会社に依頼するのがおすすめです。
Google公式の「構造化データマークアップ ヘルパー」を利用する方法もありますが、JSON-LDの形式や属性名の記述ミスがあると、AIやGoogleに認識されません。
ドコドアでは、サイトの構造や目的に応じて最適な構造化データを設計・実装しています。
(→ お問い合わせはこちら)
Q5. LLMOと従来のSEOはどう違うのですか?
A. 従来のSEOは「検索エンジンに評価される」ための最適化でした。
一方、LLMOは「AIに理解・引用される」ための最適化です。
つまり、AI検索結果(AI Overview や Perplexity.ai など)で自社の情報が引用されるよう、
構造化データや一次情報を整備しておくことが重要です。
(関連記事:生成AIを活用したSEO対策:検索順位とAIによる引用を両立させる戦略)
Q6. 構造化データを導入するタイミングはいつが良いですか?
A. 新規サイトであれば初期設計段階から組み込むのが理想です。
既存サイトの場合も、リニューアルやSEO改善のタイミングで導入すれば十分効果があります。
特に、FAQやHowToなど明確な情報構造を持つコンテンツは、構造化データと相性が抜群です。
Q7. どのように効果を確認できますか?
A. Google Search Consoleの「リッチリザルト レポート」で検出結果を確認できます。
また、ChatGPT・Gemini・Bing CopilotなどのAI検索で自社名や記事タイトルを検索し、AI回答内で引用されているかも確認してみましょう。
AIが正しく理解・引用している場合、LLMO対策が効果を発揮しています。
(参考:Google「リッチリザルトテスト」)
Q8. 構造化データとE-E-A-Tの関係は?
A. 構造化データはE-E-A-Tの「信頼性」「専門性」を補強する要素です。
AIは構造的に整理された一次情報を好み、著者情報(ProfilePage構造化データ)や企業情報(Organization構造化データ)が充実しているほど、コンテンツの信頼度が高まります。
Q9. ドコドアでは構造化データの設計や実装も依頼できますか?
A. はい、可能です。
ドコドアでは、SEOとLLMOを両立したWebサイト設計・構造化データの実装支援を行っています。
Web担当者様やマーケティング部門の方でもわかりやすく運用できるよう、運用サポートもご提供しています。
詳しくは「LLMO/SEO対策」ページからお気軽にお問い合わせください。
Q10. 将来的に構造化データの基準は変わりますか?
A. はい、GoogleやSchema.orgの仕様は年々更新されています。
AI検索時代においては、より細かく構造化された情報が重視される傾向があります。
そのため、定期的に構造化データのメンテナンスを行うことが推奨されます。
(参考:Schema.org公式サイト)

ドコドア マーケティング部
有資格:Google広告認定資格、Googleアナリティクス個人認定資格など